python版本 3.8
安装以下插件
pip3 install requests
pip3 install json
pip3 install lxml
pip3 install selenium
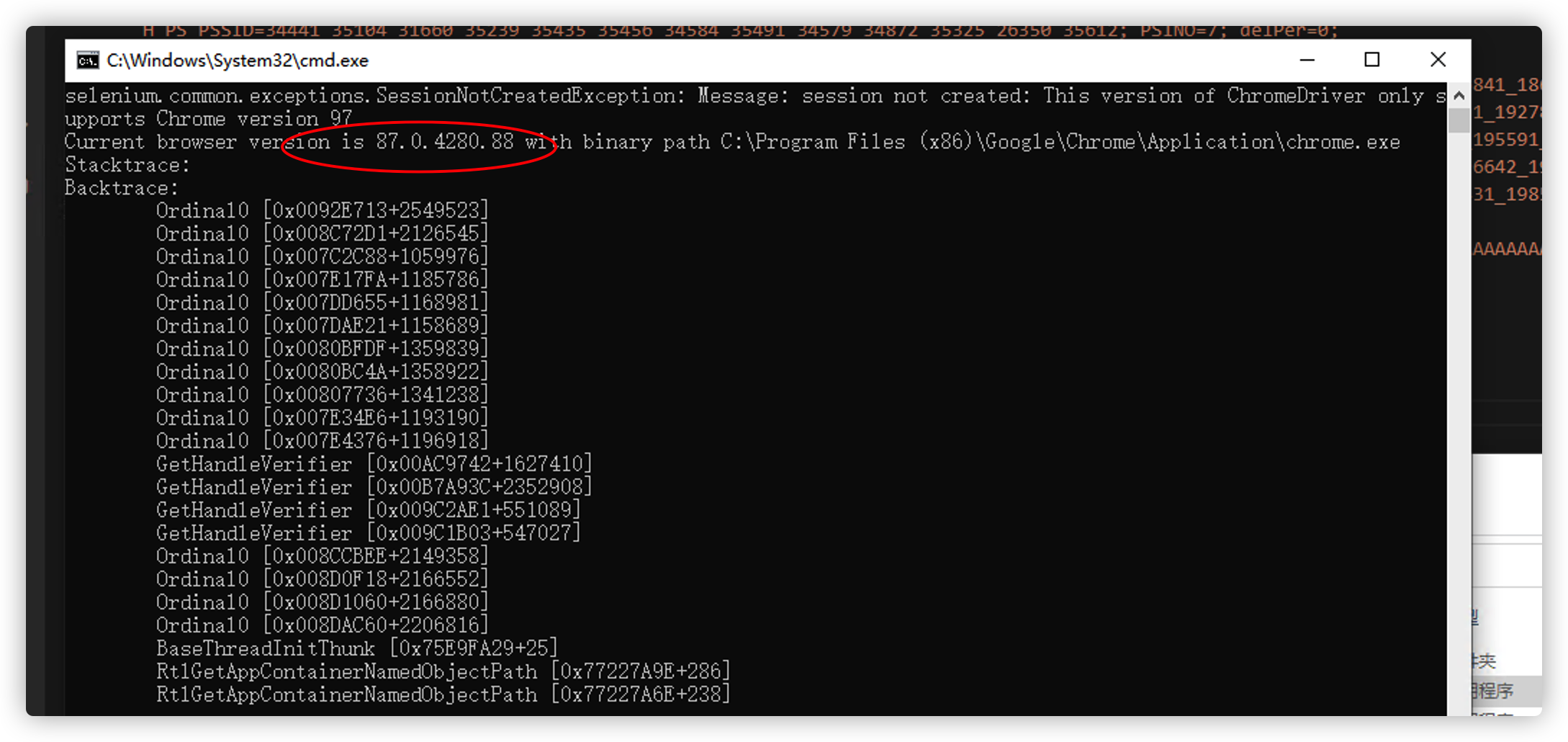
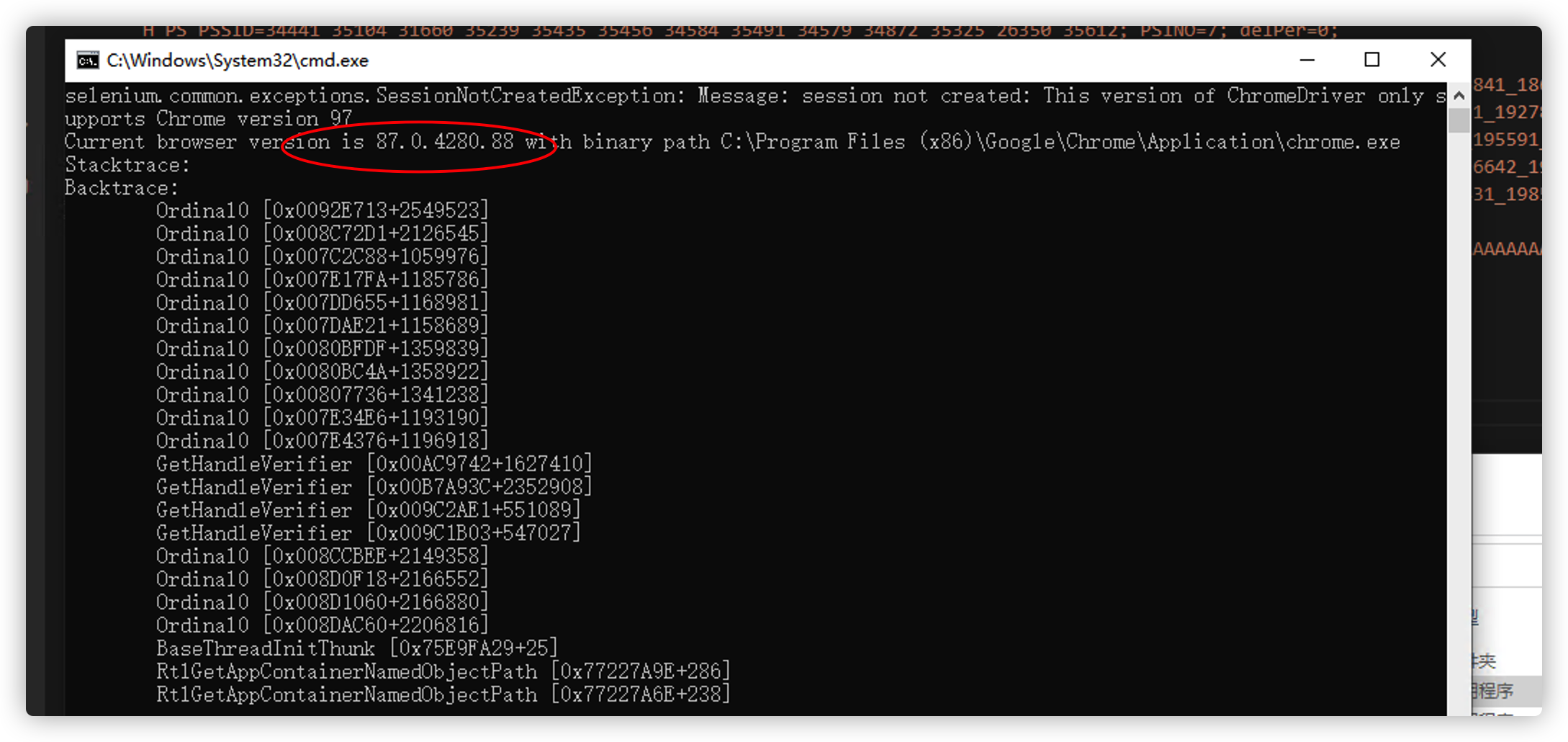
然后到到https://chromedriver.storage.googleapis.com/index.html 下载对应版本谷歌
浏览器驱动 放到本目录覆蓋chromedriver.exe。
如果不知道版本,执行一下 python main.py
github地址
https://github.com/linwoodpendleton/baidusoulu
如下图:
原码:
code:
import json
import random
import requests
import time
from random import randint
from lxml import etree
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.service import Service
chrome_options = Options()
cookies_str = 'BDORZ=xxxooo; BA_HECTOR=xxxooo; BDRCVFR[xxxoo]=xxxooo; H_PS_PSSID=xxxooo; H_WISE_SIDS=xxxooo' #百度cookies直接浏览器复制过来即可
chrome_options.add_argument("--start-maximized")
s = Service('chromedriver.exe') #谷歌浏览器驱动,到https://chromedriver.storage.googleapis.com/index.html下载对应版本
driver = webdriver.Chrome(service=s, options=chrome_options)
driver.implicitly_wait(10)
driver.get('http://www.baidu.com')
def cookies_to_dict(cookie):
cookies = cookie.split("; ")
for co in cookies:
cookieDict = {}
co = co.strip()
p = co.split('=')
value = co.replace(p[0] + '=', '').replace('"', '')
cookieDict["name"] = p[0]
cookieDict["value"] = value
driver.add_cookie(cookieDict)
def check_index_number(url):
"""
查询网址被百度收录的数量
:param url: 要查询的网址
:return: 返回被百度收录的数量
"""
url_a = 'https://www.baidu.com/s?wd=site%3A'
url_b = '&pn=1'
joinUrl = url_a + url + url_b
try:
cookies_to_dict(cookies_str)
driver.implicitly_wait(10)
driver.get(joinUrl) # 获取网页
except:
return ' '
try:
index_number = driver.find_element(By.XPATH,'//[@id="1"]/div/div[1]/div/p[3]/span/b').text
try:
yanzen = driver.find_element(By.XPATH,'//[@id="pass-slide-tipInfo62"]').text
except:
yanzen = None
except:
index_number = 0
yanzen = ''
pass
return index_number,yanzen
def getUrl(filepath):
with open(filepath, "r") as f:
f = f.readlines()
return f
def get_hostloc(url):
cookies_to_dict(cookies_str)
try:
driver.get(url) # 获取网页
driver.implicitly_wait(10)
except:
return ' '
try:
yanzen = driver.find_element(By.XPATH, '/html/body/div[4]/div[1]/div/p[1]')
except:
yanzen = None
page_source = driver.find_element(By.XPATH,"//body").text
return page_source,yanzen
def isindex(link):
link = link.replace("http://", "")
link = link.replace("https://", "").replace("/", "%2F")
url = link
url = "http://www.baidu.com/s?wd=" + url
html,yanzen = get_hostloc(url)
with open("result.txt", 'a') as f:
if "没有找到与" in html or "没有找到该URL" in html or html=='':
if yanzen:
print(link, "出现验证码")
else:
print(link, "未收录")
else:
if yanzen:
print(link, "出现验证码")
else:
print(link, "收录")
indexed_number, yanzen = check_index_number(link)
if yanzen:
print(link, "出现验证码")
f.write(link + '\t出现验证码\n')
else:
f.write(link + '\t' + str(indexed_number) + '\n')
def main():
filepath = "url.txt" # 待查询的URL链接文本,一行一个
urls = getUrl(filepath)
for url in urls:
url = url.strip()
isindex(url)
if name == 'main':
main()